Clusterbetrieb¶
Allegra kann in einer geclusterten Umgebung betrieben werden, d.h. eine Allegra-Instanz kann auf mehreren Servern laufen. Dieser Abschnitt gibt Beispiele für mögliche Konfigurationen und erklärt, wie sich Allegra in einer geclusterten Umgebung verhält.
Cluster-Konfigurationen¶
Für Webanwendungen gibt es zwei Arten von Clustern: Hochverfügbarkeitscluster (HA) und Lastausgleichscluster.
Mit einem Hochverfügbarkeits-Cluster können Sie die Verfügbarkeit des Allegra-Dienstes verbessern, um zum Beispiel einen 24/7-Betrieb zu gewährleisten. Ein HA-Cluster arbeitet mit redundanten Knoten, die bei einem Ausfall von Systemkomponenten zur Bereitstellung von Diensten verwendet werden. Die gängigste Größe für einen HA-Cluster sind zwei Knoten, was die Mindestanforderung für die Redundanz darstellt. Durch die Verwendung von Redundanz eliminieren HA-Cluster-Implementierungen einzelne Fehlerpunkte.
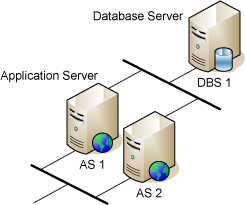
Die Abbildung unten zeigt einen einfachen HA-Cluster mit zwei Anwendungsservern und einem Datenbankserver. Der Datenbankserver ist nicht redundant, aber es wäre möglich, einen der Anwendungsserver als redundanten Datenbankserver zu verwenden. Der Router, der zwischen Anwendungsserver 1 und Anwendungsserver 2 umschaltet, ist hier nicht dargestellt.
Der Zweck eines Load-Balancing-Clusters besteht darin, eine Arbeitslast gleichmäßig auf mehrere Backend-Knoten zu verteilen. In der Regel wird der Cluster mit mehreren redundanten Load-Balancing-Frontends konfiguriert. Da jedes Element in einem Load-Balancing-Cluster den vollen Service bieten muss, kann man es sich wie ein aktives/HA-Cluster vorstellen, bei dem alle verfügbaren Server Anfragen verarbeiten.
Die folgende Abbildung zeigt eine recht große Konfiguration mit einem Load Balancer, fünf Anwendungsservern, zwei Datenbankservern und zwei Dateiservern.
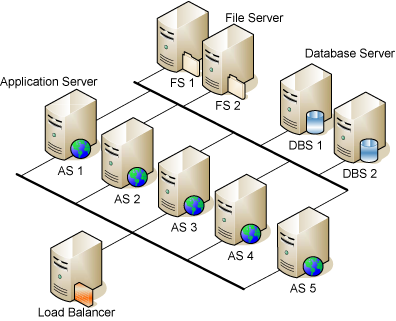
Alle Anwendungsserver arbeiten mit einer einzigen Datenbank, die redundant über zwei Datenbankserver bedient wird. Die Anhänge und Volltext-Suchindizes werden auf einem einzigen Dateiserver gehalten, der auch ein Backup hat. Die Sicherung des Dateiservers wird dem Betriebssystem überlassen, Allegra bietet dafür keine Unterstützung.
Das Datenbankmanagementsystem muss sich um die Synchronisation zwischen dem ursprünglichen Datenbankserver und dem Backup-Datenbankserver kümmern.
Die gesamte Kommunikation zwischen den verschiedenen Allegra Anwendungsservern eines Clusters wird über die Datenbank abgewickelt. Es besteht keine Notwendigkeit, spezielle Ports für die Kommunikation zwischen den Anwendungsservern zu öffnen oder gepatchte virtuelle Java-Maschinen zu verwenden.
Bemerkung
Für den Betrieb in einer Cluster-Umgebung ist in Allegra grundsätzlich keine Konfiguration erforderlich. Wenn Sie mehrere Allegra-Instanzen mit der gleichen Datenbank verbinden, geht Allegra automatisch in den Cluster-Betriebsmodus über. Sie benötigen jedoch einen entsprechenden Lizenzschlüssel, der alle Anwendungsserver einschließt, die Sie mit dieser Datenbank verbinden.
Viele andere Konfigurationen sind möglich. Zum Beispiel kann einer der Anwendungsserver gleichzeitig der Dateiserver sein. Oder der Datenbankserver und der Dateiserver können auf der gleichen Hardware installiert werden. Allegra selbst kümmert sich nicht um all dies, solange Sie sicherstellen, dass Sie genau einen Zugriffspunkt (JDBC URL) für die Datenbank und genau einen Dateipfad zu den Attachment- und Index-Verzeichnissen für alle Allegra-Instanzen dieses Clusters haben.
Startup-Verhalten¶
Wenn eine Allegra-Instanz gestartet wird, registriert sie sich selbst als Knoten in der Datenbank.
Dann wird die Datenbank nach anderen Knoten durchsucht. Wenn es Knoten in der Datenbank gibt, die
ihren Eintrag innerhalb einer bestimmten Timeout-Periode (Standard ist 5 Minuten, kann in der Datei
WEB-INF/quartz-jobs.xml eingestellt werden) nicht aktualisiert haben, wird dieser Eintrag aus
der Tabelle gelöscht.
Danach versucht Allegra, sich selbst als Master-Knoten zu setzen, es sei denn, es gibt bereits einen anderen Knoten, der als Master-Knoten markiert ist. Wenn dies der einzige Knoten ist, ist die Operation sofort erfolgreich. Andernfalls kann es bis zur Timeout-Periode dauern, bis ein neuer Master-Knoten vollständig eingerichtet ist.
Der Master-Knoten ist verantwortlich für
das Aktualisieren des Volltextsuchindexes
Abrufen von E-Mails von einem E-Mail-Server, wenn die Übermittlung von Artikeln per E-Mail aktiviert ist.
Ansonsten verhält sich der Master-Knoten wie ein normaler Knoten.
Master-Knoten fällt aus¶
Wenn der Master-Knoten ausfällt, wird die Volltextsuche vorübergehend nicht aktualisiert. Es gehen jedoch keine Aktivitäten verloren, die eine Aktualisierung des Volltextsuchindexes erfordern, sie werden in der Datenbank gespeichert.
Außerdem ist der Abruf von E-Mails vom E-Mail-Server vorübergehend deaktiviert. Auch hier gehen keine Eingaben verloren, da sie auf dem E-Mail-Server gespeichert sind.
Nach maximal einer Timeout-Periode (Standardwert ist 5 Minuten, festgelegt in
WEB-INF/quartz-jobs.xml) beginnt die Verhandlung zwischen den verbleibenden Knoten,
wer den ursprünglichen Master-Knoten ersetzt. Das Ergebnis ist zufällig. Der neue
Master-Knoten beginnt mit der Aktualisierung des Volltextsuchindex und dem
Abruf von E-Mails vom E-Mail-Server.
Der Ausfall eines Master-Knotens führt also zu einer leicht verringerten Leistung und zu einer Verzögerung von etwa 5 Minuten bei der Aktualisierung des Volltextsuchindexes.
Ausfall eines regulären Knotens¶
Wenn ein regulärer Knoten ausfällt, kommt es zu einem gewissen Leistungsabfall.
Die anderen Knoten benötigen weniger als die Timeout-Periode (Standard ist 5 Minuten,
eingestellt in WEB-INF/quartz-jobs.xml), um zu erkennen, dass ein Knoten ausgefallen
ist. Dies hat jedoch keine weiteren Konsequenzen.
Erzwungener Wechsel des Master-Knotens¶
Normalerweise verhandeln alle Anwendungsknoten untereinander, wer der Master-Knoten werden soll. Das Ergebnis ist zufällig.
Es ist jedoch möglich, einen der Knoten dazu zu zwingen, der Master-Knoten zu werden. Dazu muss der derzeitige Master-Knoten angewiesen werden, seine auf den Master-Knoten bezogenen Operationen, wie die Aktualisierung des Volltextsuchindex, einzustellen und dem neuen Master-Knoten Platz zu machen. Dieser Prozess kann bis zur Timeout-Periode (standardmäßig 5 Minuten) dauern, bevor der neue Knoten seine Verantwortung als neuer Master-Knoten übernehmen kann.